












Keerthi Ganesh
AI/ML Developer
In the realm of artificial intelligence, the pursuit of more accurate and contextually relevant information retrieval has led to significant advancements. One such evolution is from Retrieval-Augmented Generation (RAG) to GraphRAG, a concept detailed in a recent Microsoft blog post.. Let's explore what RAG is, its benefits, and why the transition to GraphRAG was necessary.
What is RAG?
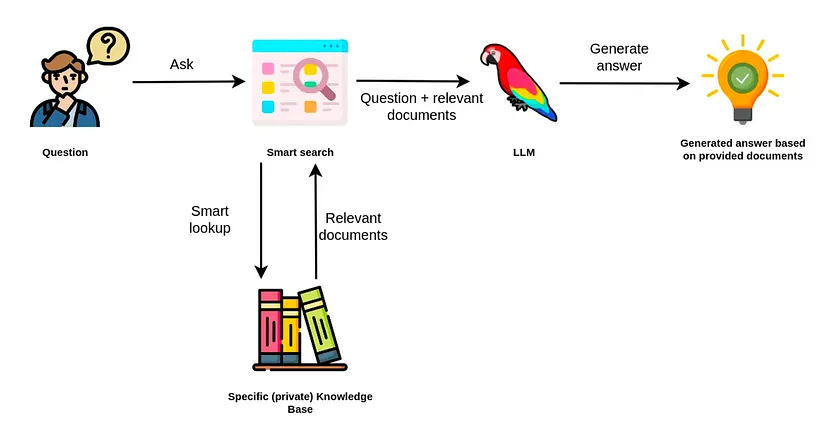
Retrieval-Augmented Generation (RAG) is a natural language querying approach designed to enhance the capabilities of large language models (LLMs) with external knowledge. Here's how it works:
- Data Collection: Collect relevant documents or information from various sources such as databases, websites, and files.
- Data Chunking: Divide the collected data into smaller, more manageable chunks for easier processing.
- Document Embeddings: Transform each chunk into a vector (embedding) that represents its semantic meaning.
- Query Embeddings: Convert the user's query into a vector format to capture its semantic essence.
- Similarity Matching: Compare the query vector with the document vectors to find the most relevant data chunks.
- Response Generation: Use a language model to generate a coherent and contextually accurate response based on the retrieved data chunks.
By following these steps, RAG effectively leverages both retrieval and generation techniques to enhance the accuracy and relevance of responses, making it a powerful tool for various applications.
The Need for GraphRAG
While RAG significantly improved the performance of LLMs, there was still room for enhancement, especially in handling complex queries and large datasets. This led to the development of GraphRAG, which builds upon the foundation of RAG but introduces a more sophisticated approach to indexing and retrieval.
Introduction to GraphRAG
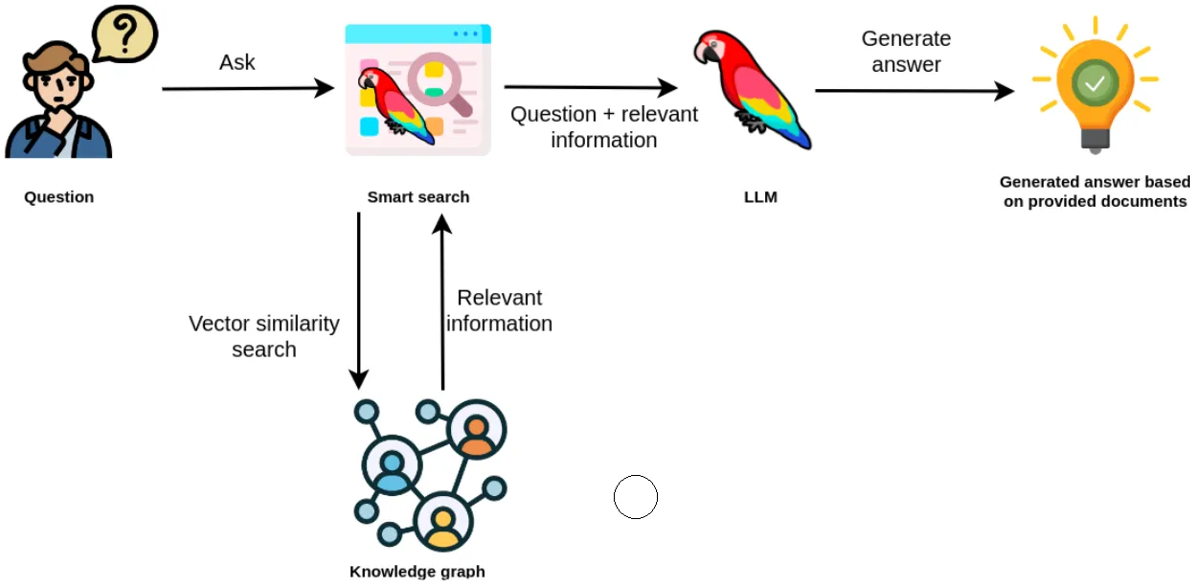
GraphRAG takes the concept of RAG a step further by introducing a two-step process that leverages knowledge graphs derived from LLMs. Here's how GraphRAG works:
Step 1: Indexing with Knowledge Graphs
The first step in GraphRAG involves creating LLM-derived knowledge graphs from private data. These knowledge graphs act as a form of memory representation for the LLM, capturing semantic relationships within the data. This enriched representation allows for more effective information retrieval in subsequent steps.
Step 2: LLM Orchestration
In the second step, the pre-built indices (knowledge graphs) are utilized to orchestrate the LLMs. This orchestration mechanism leverages the knowledge graphs to enhance retrieval-augmented generation (RAG) operations, leading to more accurate and contextually relevant results.
Key Differentiators of GraphRAG
GraphRAG offers several advantages that set it apart from traditional RAG methods:
- Enhanced Search Relevancy: By having a holistic view of the semantics across the entire dataset, GraphRAG improves the relevance of search results.
- Enabling New Scenarios: It supports complex scenarios that require large context windows, such as holistic dataset analysis, trend summarization, and data aggregation.
How GraphRAG Works
To understand GraphRAG, it's essential to compare it with baseline RAG. In baseline RAG, a private dataset is chunked into embeddings and stored in a vector database. Nearest neighbour searches are performed to augment the context window.
GraphRAG parallels this process but adds an extra layer of reasoning. Here's a step-by-step breakdown:
- Text Chunking and Reasoning: The same text chunks are used, but the LLM performs reasoning operations over each sentence in the dataset.
- Entity and Relationship Extraction: Named entity recognition (NER) identifies entities in the text, but GraphRAG goes further by determining the relationships and the strength of those relationships between entities.
- Knowledge Graph Creation: The extracted relationships form a knowledge graph with nodes (entities) and edges (relationships).
Example:
- Sentence: "The PO leader Sylvia Mar took the stage with Luo Jack, founder of Save Our Wildlands."
- GraphRAG identifies Sylvia Mar's strong relation to PO (she is the leader) and a weak relation to Save Our Wildlands (shared stage but not leader).
This deeper understanding allows GraphRAG to create weighted graphs that surpass traditional NER's co-occurrence networks, enabling richer semantic analysis.
RAG Systems Comparison
- Baseline RAG: Struggles with specific queries, often failing to provide comprehensive answers.
- Improved RAG: Performs better with tuning and prompt engineering but still lacks depth in complex queries.
- GraphRAG: Excels by providing detailed and accurate responses, leveraging the knowledge graph for richer context and precise information retrieval.
Building and Utilizing Knowledge Graphs
Once the knowledge graphs are created, they enable advanced functionalities:
- Graph Machine Learning: Semantic aggregations and hierarchical clustering can be performed on the graphs, creating labeled structures that allow for granular filtering and querying.
- Versatile End Use Cases: The knowledge graphs can be leveraged for various applications, including dataset question generation, summarization, and Q&A.
Code Implementation
Let's walk through the GraphRAG use case, which utilizes medical documents containing information from the "Disease Handbook for Childcare Providers." This handbook provides comprehensive details on preventing, managing, and reporting infectious diseases in childcare settings. We will also use a basic RAG system to compare the responses from each system.
To download the pdf
Collab Link Graph_rag_code
Required packages needed
pip install llama-index
pip install llama-index-llms-openai
pip install langchain
Importing Libraries
import os
from llama_index.core import (KnowledgeGraphIndex,ServiceContext,SimpleDirectoryReader)
from llama_index.core.indices.vector_store.base import VectorStoreIndex
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.core.graph_stores import SimpleGraphStore
from llama_index.core import StorageContext
Preprocess Data & define LLM
documents = SimpleDirectoryReader(input_files=["disease-handbook-complete.pdf"]).load_data()
llm = OpenAI(temperature=0, model="gpt-4-turbo",api_key=API_KEY)
Settings.llm = llm
Settings.chunk_size = 512
service_context = ServiceContext.from_defaults(llm=llm, chunk_size=512)
Building the Knowledge Graph
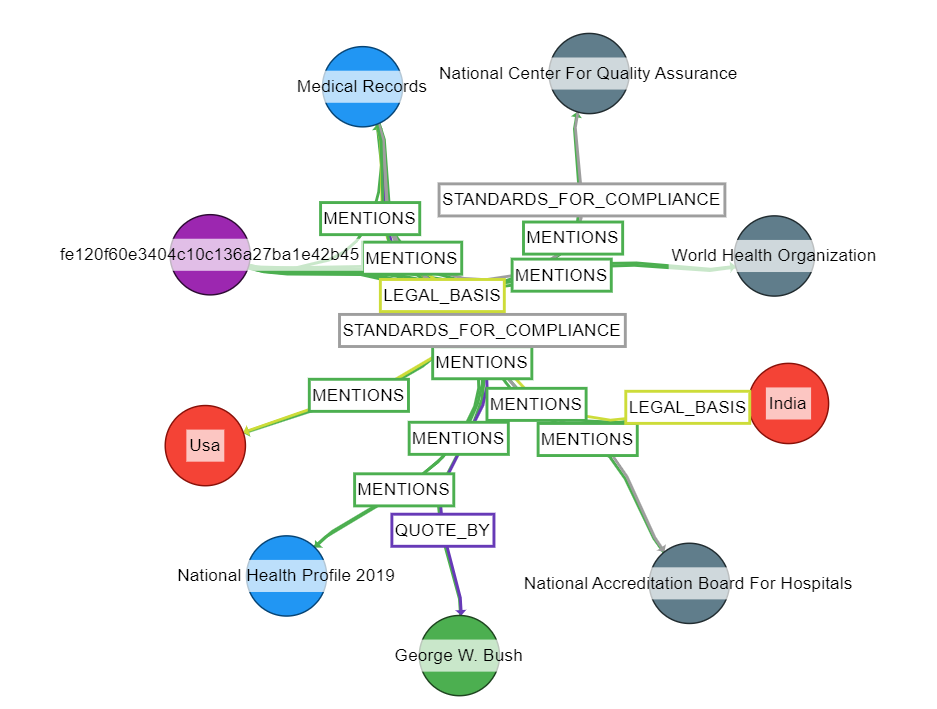
The Knowledge Graph was created using an LLM. This was accomplished by utilizing the KnowledgeGraphIndex from LlamaIndex, which extracts entities and relationships with the help of the LLM and then stores them in the SimpleGraphStore().
graph_store = SimpleGraphStore()
storage_context = StorageContext.from_defaults(graph_store=graph_store)
kg_index = KnowledgeGraphIndex.from_documents(
documents,
max_triplets_per_chunk=2,
storage_context=storage_context,
service_context=service_context)
Set up a VectorStoreIndex for Retrieval-Augmented Generation (RAG)
To contrast with the VectorDB-based RAG, we will also establish a VectorStoreIndex. During its setup, the same data source will be divided into chunks, and their embeddings will be created. During RAG queries, the top-k related embeddings will be vector-searched using the embedding of the query.
vector_index = VectorStoreIndex.from_documents(
documents,
service_context=service_context
)
Save and Load Llama Indexes from Disk
Both the KnowledgeGraphIndex and VectorStoreIndex are created once. Subsequently, their in-memory contexts can be saved to disk, enabling them to be reloaded and reused at any time.
dir_vector= folder_path_vector
dir_graph= folder_path_graph
kg_index.storage_context.persist(persist_dir=dir_graph)
vector_index.storage_context.persist(persist_dir=dir_vector)
Restoring the Index from Disk
This allows us to restore the index from disk as follows:
from llama_index.core import load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir=dir_graph, graph_store=graph_store)
kg_index = load_index_from_storage(
storage_context=storage_context,
service_context=service_context,
max_triplets_per_chunk=10,
include_embeddings=True,
)
storage_context_vector = StorageContext.from_defaults(persist_dir=dir_vector)
vector_index = load_index_from_storage(
service_context=service_context,
storage_context=storage_context_vector)
RAG Query Engines Setup
Vector RAG finds the top-k semantically related document chunks to use as context for synthesizing the answer, while GraphRAG uses SubGraphs related to entities in the task or question as context.
kg_rag_query_engine = kg_index.as_query_engine(
include_text=False,
retriever_mode="keyword",
response_mode="tree_summarize",
)
vector_rag_query_engine = vector_index.as_query_engine()
Queries with RAG Engines
Lets try to ask multiple question to each engines and we can analyse how they perform, as of now lets try with the question
“What steps should be taken to prevent the spread of conjunctivitis (pink eye) in a childcare setting?”
Query with GraphRAG
result_graph_rag = kg_rag_query_engine.query
(
"What steps should be taken to prevent the spread of conjunctivitis (pink eye) in a childcare setting?"
)
Response

Query with RAG
result_vector_rag = vector_rag_query_engine.query
(
"What steps should be taken to prevent the spread of conjunctivitis (pink eye) in a childcare setting?"
)
Response

Observations from Both Responses
To evaluate the responses from GraphRAG and Vector Rag, we need to compare the thoroughness, accuracy, and comprehensiveness of their provided steps to prevent the spread of conjunctivitis in a childcare setting.
Comparison
Thoroughness
- GraphRAG response provides a broader range of preventive measures, covering hand hygiene, avoiding eye contact, not sharing personal items, cleaning surfaces, education for staff and parents, isolation of symptomatic children, and consultation with healthcare providers.
- Vector Rag response focuses on hygiene practices related to washing articles, hand washing, and using separate items for each child but does not address other preventive measures such as educating staff and parents, isolating symptomatic children, or consulting healthcare providers.
Accuracy
- Both responses are accurate in their recommendations, but GraphRAG includes additional important steps that Vector Rag does not mention.
- Comprehensiveness
- GraphRAG is more comprehensive, addressing a wider variety of actions that should be taken to prevent the spread of conjunctivitis.
- Vector Rag is less comprehensive and more focused on specific hygiene practices without addressing some broader preventive measures.
Question-Response Comparison Table
1. Chickenpox, as directed by the Bureau of Infectious Disease Control.
2. Shingles, if the lesions cannot be covered by clothing or a dressing until the lesions have crusted.
3. Rash with fever or joint pain, until diagnosed not to be measles or rubella.
4. Measles, as directed by the Bureau of Infectious Disease Control.
5. Rubella, as directed by the Bureau of Infectious Disease Control.
6. Diarrhea illness, nausea, and/or vomiting if there are three or more episodes of diarrhea during the previous 24 hours or blood in stools, until 48 hours after the resolution of symptoms unless vomiting is identified as a non-communicable condition such as pregnancy or digestive disorder or deemed non-infectious by a healthcare professional.
7. Hepatitis A virus, as directed by the Bureau of Infectious Disease Control.
1. Wet hands with clean, running water (warm or cold), and apply soap.
2. Lather hands by rubbing them together with the soap, covering all surfaces of the hands, including the backs, between the fingers, and under the nails.
3. Scrub hands for at least 20 seconds. A helpful way to time this is to hum the "Happy Birthday" song twice.
4. Rinse hands well under clean, running water.
5. Dry hands using a clean towel or air dry them.
It is important to supervise young children to ensure they follow these steps properly. Additionally, hand washing should be performed at key times such as before eating, after using the toilet, after blowing one's nose, coughing, or sneezing, and after touching garbage.
| Questions | GraphRAG | RAG |
|---|---|---|
| What are the immunisation requirements for children attending childcare in New Hampshire according to the Disease Handbook for Childcare Providers? | The Disease Handbook for Childcare Providers specifies that children attending childcare in New Hampshire must be immunised against diphtheria, tetanus, pertussis, polio, measles, mumps, rubella, hepatitis B, and varicella. | All children in daycare must be immunised appropriately for their age, in accordance with the NH State Law: RSA 141:C-20. Specific information about immunisation schedules can be found in the Immunization Requirements Section of the handbook and on the appropriate fact sheets. |
| What are the symptoms of chickenpox and how is it spread? | Chickenpox is characterised by symptoms such as an itchy rash that forms blisters, fever, tiredness, loss of appetite, and headache. It is spread through direct contact with the rash, inhalation of airborne droplets from an infected person's coughing or sneezing, or sharing drinks or utensils with someone who has chickenpox. | The symptoms of chickenpox typically begin with a mild fever followed by an itchy rash. The rash starts as crops of small red bumps on the stomach or back and then spreads to the face and limbs. |
| What are the guidelines for excluding staff from a childcare setting due to illness? | Staff should be excluded from a childcare setting due to illness under the following conditions: 1. Chickenpox, as directed by the Bureau of Infectious Disease Control. 2. Shingles, if the lesions cannot be covered by clothing or a dressing until the lesions have crusted. 3. Rash with fever or joint pain, until diagnosed not to be measles or rubella. 4. Measles, as directed by the Bureau of Infectious Disease Control. 5. Rubella, as directed by the Bureau of Infectious Disease Control. 6. Diarrhea illness, nausea, and/or vomiting if there are three or more episodes of diarrhea during the previous 24 hours or blood in stools, until 48 hours after the resolution of symptoms unless vomiting is identified as a non-communicable condition such as pregnancy or digestive disorder or deemed non-infectious by a healthcare professional. 7. Hepatitis A virus, as directed by the Bureau of Infectious Disease Control. |
Staff should be excluded from a childcare setting if they exhibit symptoms of contagious illnesses such as fever, vomiting, diarrhea, or severe respiratory symptoms. They should remain out of the setting until they are symptom-free for at least 24 hours without the use of medication. This helps prevent the spread of illness to children and other staff members. |
| What are the proper hand washing techniques recommended for children and staff in a childcare setting? | The proper hand washing techniques recommended for children and staff in a childcare setting include the following steps: 1. Wet hands with clean, running water (warm or cold), and apply soap. 2. Lather hands by rubbing them together with the soap, covering all surfaces of the hands, including the backs, between the fingers, and under the nails. 3. Scrub hands for at least 20 seconds. A helpful way to time this is to hum the "Happy Birthday" song twice. 4. Rinse hands well under clean, running water. 5. Dry hands using a clean towel or air dry them. It is important to supervise young children to ensure they follow these steps properly. Additionally, hand washing should be performed at key times such as before eating, after using the toilet, after blowing one's nose, coughing, or sneezing, and after touching garbage. |
The proper hand washing techniques recommended for children and staff in a childcare setting include washing hands well before and after touching food, and ensuring that hands are rinsed thoroughly. After washing, hands should be dried using a single-use towel, such as a paper towel. It is also advised to turn off the water using a paper towel instead of bare hands to avoid recontaminating the hands. These steps help prevent the spread of foodborne illnesses and maintain a hygienic environment in childcare settings. |
GraphRAG responded better because it provided a more thorough and comprehensive set of steps, covering a broader range of preventive actions and ensuring a holistic approach to managing conjunctivitis in a childcare setting.
Conclusion
The journey from RAG to GraphRAG marks a significant milestone in the evolution of information retrieval and generation using large language models. By leveraging LLM-derived knowledge graphs, GraphRAG not only enhances the relevancy of search results but also opens up new possibilities for complex data analysis and contextual understanding. This advanced approach allows for a more nuanced and interconnected understanding of data, paving the way for more accurate and insightful AI-driven solutions. As we continue to harness the power of GraphRAG, we move closer to unlocking the full potential of AI in transforming how we interact with and derive insights from vast datasets.





