
Threads:
We all know what a process is it is a unit of
work with a single thread of control.Thread is also a lightweight
process. The main difference between process and threads is that
threads within the same process run in shared memory space, while
processes run in separate memory spaces.
Using threads
helps to achieve concurrency. A process can have multiple threads.
Each thread will act as a separate process
Today we
will learn about how to use threads in ruby to achieve better
performance.Before diving into code, let’s get familiar with some
necessary concepts.
Scheduler:
The main job of the scheduler is to move the
process from queues to CPU or from one queue to a different queue
In actual OS, there will be more schedulers. For simplicity’s
sake, we define two schedulers: job scheduler and CPU scheduler
and ready-queue to store the process metadata
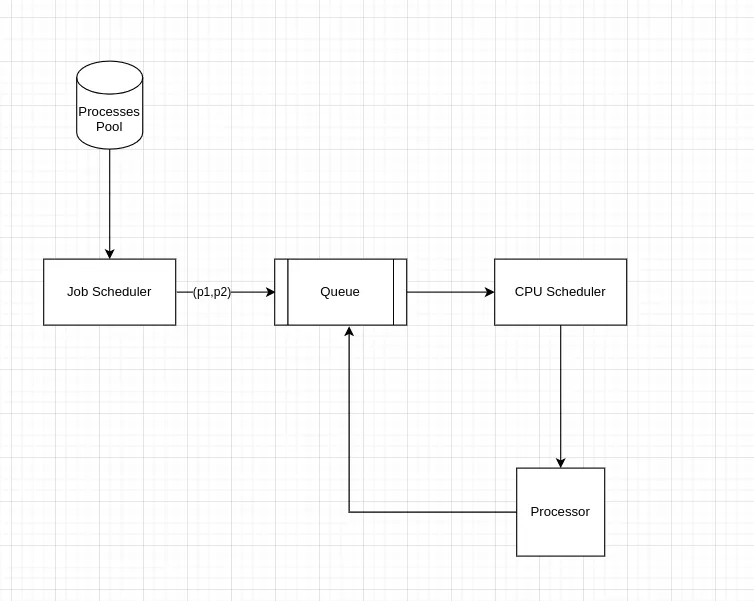
When a process is generated we store the process in the process
pool. The job scheduler will take the process from the pool and
add it to the ready queue, Cpu Scheduler will take the process
which is ready to execute from the Queue and allocates CPU
resources to it.
CPU Scheduler works based on round robin algorithm and it will
allocate constant to each process from the queue, once allocated
time is done, It will need to save the context of the current
running process and restore the context of the next available
process from the queue, this is called context switching. context
switch time is purely overhead
Context switch time for threads is less compared to single thread
process because threads within the same process run in a shared
memory space
Let’s create a simple method in ruby and execute it in IRB or
console
def step(v)
sleep(v/10.0) # suspends the execution
puts "step#{v}"
end
step method accepts integer/float as input sleep for
(input/10.0) seconds then prints a statement in the console
Lets do some benchmark analysis w/o threads on this method
Benchmark.realtime do
10.times do
step(1)
step(2)
step(3)
end
end
#took 6.010479167001904 seconds
Benchmark.realtime do
threads = []
100.times do
threads << Thread.new { step(1) }
threads << Thread.new { step(2) }
threads << Thread.new { step(3) }
end
threads.each(&:join)
end # 0.4057327560003614 seconds
In the first scenario, we called the method 30 times, total
execution time is 6.01 seconds.
In the second scenario, we called the method 300 times total
execution time is 0.4 seconds
We spawned a new thread every time when we call the step, all
threads are executed concurrently with minimum context switch time
DataRace:
DataRace occurs when one thread access a mutable
object while another thread writing to it. lets consider below
example
val = [0, 0]
threads = (0...5).map do
Thread.new do
1000000.times do
val.map! { |c| c + 1 }
end
end
end
threads.each(&:join)
puts val.to_s
#result [3009784, 4901092]
we created an array that contains 6 objects each value of the
object is 0. we spawned 5 threads in each thread we are updating
the values of objects inside the array
we expect the output should be [5000000, 5000000] instead we got
[3711034,4481783]. Threads will execute in any order we don't have
control over that, here val array is accessed by all the threads
if multiple threads modify the same object there is a chance for
race condition
consider one scenario where val[0] = 100 and val[1] =100 thread t1
executing this line val.map! { |c| c + 1 } and thread t2
executing this line 1000000.times do
If you examine carefully we are doing multiple operations in this
step
val.map! { |c| c + 1 }
- we are reading the value val[0] from memory
- we are incrementing the value by 1
- we update the new value in the memory
Imagine thread t1 got suspended by CPU before writing 101 to
memory and CPU started executing the code. when t2 reads the
val[0] from memory it will get 100 instead of 101.
t2 incremented and updated the val[0] and val[1] as 101 and 101 in
memory now t2 got suspended and t2 is resumed t2 will start
executing where it got paused previously (writing 101 to the
memory) it updates the val[0] as 101 in the memory this is called
race condition. The data inside the val array is corrupted, to
avoid these conditions we can put a lock on the val array.
If any thread puts a lock on a specific section of code remaining
threads have to wait until the lock is released. Ruby provides a
mutex library to put locks on the code. we can rewrite the above
code using the mutex library
val = [0, 0]
lock = Mutex.new
threads = (0...5).map do
Thread.new do
1000000.times do
lock.synchronize do
val.map! { |c| c + 1 }
end
end
end
end
threads.each(&:join)
puts val.to_s
#result [5000000, 5000000]
Using threads to achieve execution speed is a good idea but we
have to keep eye on race conditions and avoid it using locks. And
do not create too many threads system can run out of memory ruby
provides many libraries to use threads like thread/pool, ruby also
provides
semaphores which deal with the race conditions by a
signaling mechanism
As Uncle Ben said
with great power comes great responsibility. Threads are
very powerful use them creatively and carefully.