
Large Language Models (LLMs) have become a cornerstone of modern artificial intelligence, enabling machines to understand, generate, and interact with human language in ways previously thought impossible. From powering chatbots to enhancing language translation services, LLMs are driving significant advancements across various industries. This blog provides a detailed exploration of what LLMs are, how they work, their applications, and a comprehensive guide on building and deploying your own LLM. Let’s delve into the details and uncover the full potential of LLMs.

What is an LLM?
A Large Language Model (LLM) is a type of deep learning algorithm that can understand, generate, and manipulate human language. LLMs operate by leveraging deep neural networks, particularly transformer architectures, to process large amounts of sequential data like text input. These models are pre-trained on vast datasets and can perform a variety of tasks such as language translation, text generation, and question answering.
Key Features of LLMs:
- Massive Training Data: LLMs are trained on extensive text datasets, providing a broad understanding of language.
- Deep Learning Architectures: They utilize advanced neural network architectures, particularly transformers, to process and generate text.
- Contextual Understanding: LLMs can generate contextually appropriate and coherent responses based on the input they receive.
- Generative Capabilities: These models can create new text that often resembles human-written text.
How Large Language Models Work
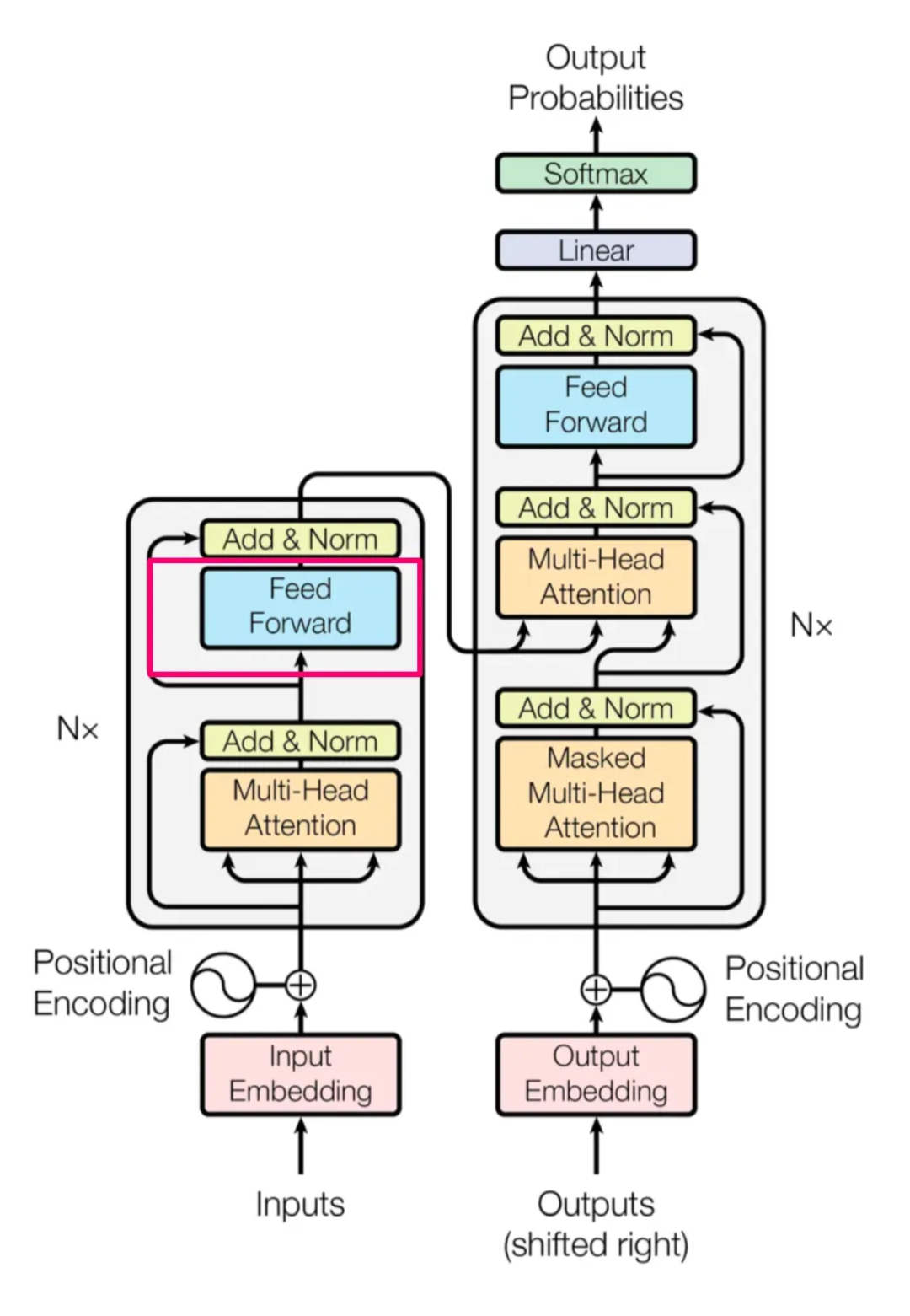
LLMs operate by leveraging deep learning techniques and neural networks, specifically transformer architectures, to process and generate text.
A Quick Recap of the Transformer Model
The transformer model, introduced in the paper “Attention is All You Need,” is the foundation of most modern LLMs. It uses self-attention mechanisms to weigh the importance of different words in a sentence, allowing the model to capture long-range dependencies and contextual relationships more effectively than previous models like RNNs and LSTMs.
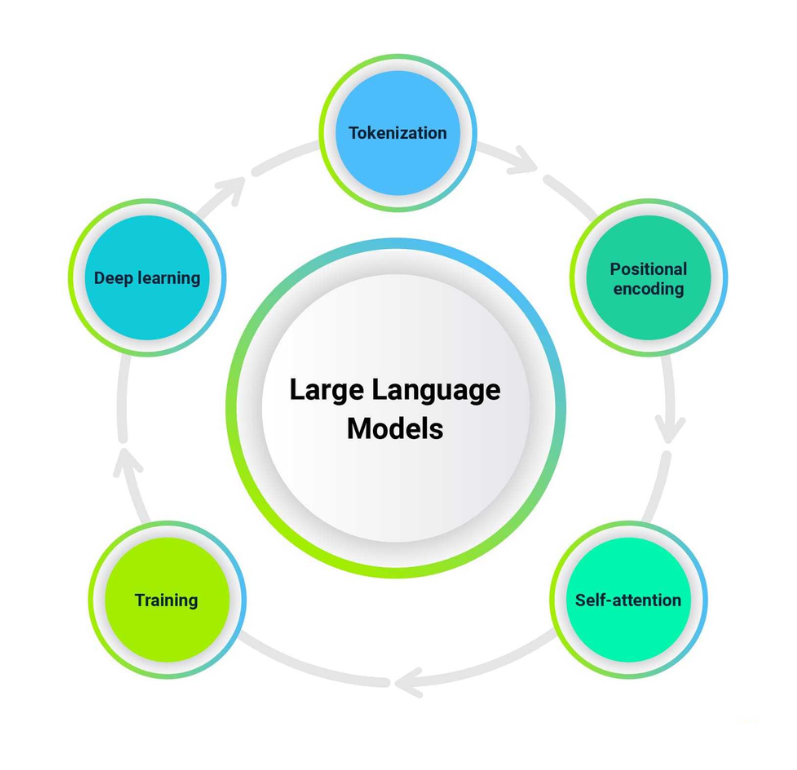
What are The Key Elements of Large Language Models?
Large Language Models (LLMs) are built on sophisticated neural network architectures, particularly transformers, which consist of several essential components that enable them to understand and generate human-like text.
1. Embedding Layer
The Embedding Layer is fundamental in transforming input text into numerical representations that the model can process. Here’s how it works:
- Tokenization: Input text is split into tokens, which are typically words or subwords.
- Mapping Tokens to Vectors: Each token is mapped to a high-dimensional vector (embedding) that represents its meaning in a continuous space.
- Learning Semantic Relationships: Embeddings are learned during the model training process and capture semantic relationships between tokens. For instance, similar words or concepts may have embeddings that are closer in the vector space.
2. Feedforward Layer
The Feedforward Layer in transformers processes the embeddings through a series of neural network operations:
- Transforming Embeddings: Each token’s embedding passes through one or more feedforward layers.
- Non-linear Transformations: These layers apply non-linear transformations to the embeddings, enhancing the model’s ability to capture complex patterns in the data.
- Activation Functions: ReLU (Rectified Linear Unit) or similar activation functions introduce non-linearity, enabling the model to learn and generalize better.
3. Recurrent Layer
In traditional recurrent neural networks (RNNs), the Recurrent Layer plays a crucial role in handling sequential data:
- Sequential Processing: Recurrent layers process one token at a time while maintaining an internal state (hidden state).
- Capturing Temporal Dependencies: They excel in capturing dependencies over time, making them suitable for tasks where the order of tokens matters, such as language modeling and machine translation.
- Challenges: However, RNNs can struggle with capturing long-range dependencies due to issues like vanishing gradients.
4. Attention Mechanism
The Attention Mechanism is a pivotal innovation in transformer architectures, facilitating parallel processing and capturing long-range dependencies efficiently:
- Self-Attention: Unlike RNNs, transformers employ self-attention mechanisms that allow tokens to attend to other tokens within the same sequence.
- Importance Weighting: Tokens weigh the importance of other tokens based on learned attention scores, focusing more on relevant tokens and less on irrelevant ones.
- Multi-Head Attention: Transformers use multiple attention heads to capture different aspects of relationships between tokens, enhancing model performance.
- Positional Encoding: Combined with positional encoding, attention mechanisms enable transformers to handle sequential data without the need for recurrence.
Also Read- Beyond Basics: Elevating AI with Reinforcement Learning from Human Feedback
Types of Large Language Models
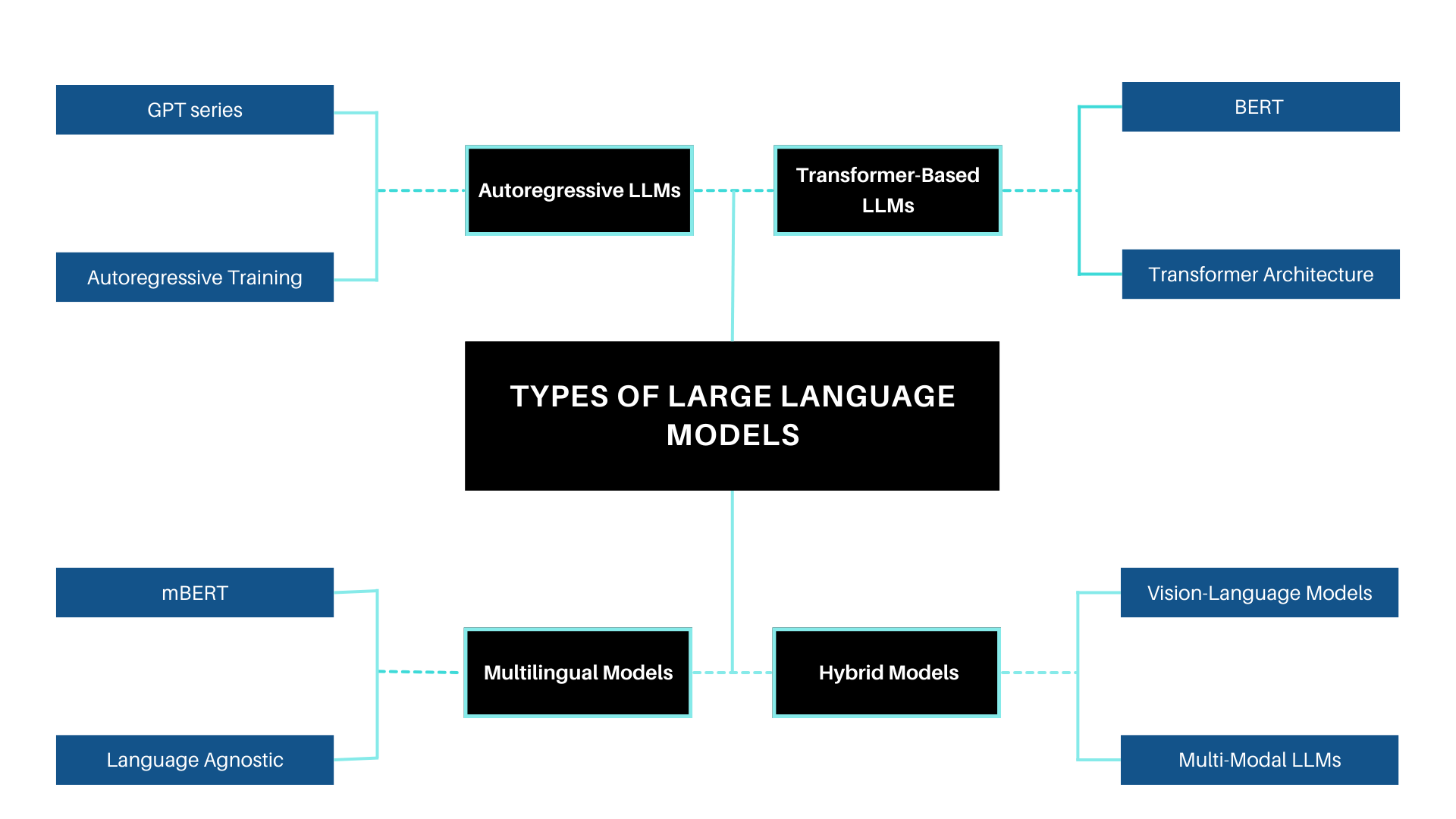
Large Language Models (LLMs) vary in architecture and functionality based on the tasks they are designed to perform. Here are some common types:
1. Autoregressive LLMs
Autoregressive LLMs generate output tokens one at a time, conditioning each prediction on previously generated tokens. They are sequential in nature and typically rely on models like:
- GPT (Generative Pre-trained Transformer) series: Developed by OpenAI, GPT models use a unidirectional transformer architecture to predict the next token based on preceding tokens.
- Autoregressive Training: These models are trained on large datasets using autoregressive methods, where the model learns to predict the probability distribution of the next token given the context.
- Use Cases: Autoregressive LLMs excel in tasks like text generation, dialogue systems, and language understanding where the order of tokens is critical.
2. Transformer-Based LLMs
Transformer-Based LLMs revolutionized natural language processing with their attention mechanisms, allowing tokens to attend to other tokens in the sequence. Key examples include:
- BERT (Bidirectional Encoder Representations from Transformers): Introduced by Google, BERT models use bidirectional transformers for tasks like language understanding and sentiment analysis.
- Transformer Architecture: These models utilize self-attention layers and feedforward neural networks to process input sequences efficiently.
- Use Cases: Transformer-based LLMs are versatile, handling tasks from language modeling to translation and information retrieval, leveraging their ability to capture context from large datasets.
3. Multilingual Models
Multilingual LLMs are designed to process and understand multiple languages within the same model architecture. Examples include:
- mBERT (Multilingual BERT): Developed by Google, mBERT is trained on multiple languages simultaneously, enabling it to perform well across various language tasks without language-specific fine-tuning.
- Language Agnostic: These models learn to generalize across languages, benefiting from shared representations and cross-lingual capabilities.
- Use Cases: Multilingual LLMs are beneficial for applications requiring language-agnostic processing, such as cross-lingual information retrieval, translation, and multilingual sentiment analysis.
4. Hybrid Models
Hybrid LLMs integrate different architectures or modalities to enhance performance across various tasks. Examples include:
- Vision-Language Models: Combining text understanding with image processing, models like CLIP (Contrastive Language-Image Pre-training) from OpenAI learn to associate images with corresponding textual descriptions.
- Multi-Modal LLMs: These models leverage multiple modalities (text, images, audio) to perform tasks beyond traditional text-based applications.
- Use Cases: Hybrid LLMs are versatile, applied in tasks requiring multimodal understanding, such as image captioning, visual question answering, and multimodal sentiment analysis.
Difference Between Generative AI and Large Language Models
While both generative AI and LLMs can produce new content, LLMs are specifically designed for text-based tasks. Generative AI encompasses a broader range of applications, including image and music generation, using models like GANs (Generative Adversarial Networks) and VAEs (Variational Autoencoders).
LLM Use Cases Across Industries
Large Language Models (LLMs) have revolutionized numerous business processes across industries, demonstrating their versatility and transformative impact:
- Conversational AI: LLMs enhance chatbots and virtual assistants by providing context-aware responses that simulate human-like interactions. This capability is crucial for improving customer service experiences and automating backend tasks.
- Content Generation: LLMs automate content creation for diverse purposes such as blog articles, marketing materials, and sales scripts. They excel in generating coherent and contextually relevant content based on input prompts.
- Research and Academia: In academia, LLMs aid in summarizing and extracting information from extensive datasets, accelerating knowledge discovery and facilitating data-driven research.
- Language Translation: LLMs break down language barriers by providing accurate translations across different languages, thereby facilitating global communication and business operations.
- Code Generation and Analysis: LLMs assist developers by generating code, identifying errors, and enhancing security measures in various programming languages. They streamline software development processes and ensure code quality.
- Sentiment Analysis: By analyzing text, LLMs determine customer sentiments and feedback at scale. This capability is essential for brands to manage their reputation, understand customer preferences, and tailor marketing strategies accordingly.
- Accessibility: LLMs contribute to accessibility by supporting text-to-speech applications and generating content in accessible formats. This aids individuals with disabilities by providing easier access to information and digital services.
- Industry-Specific Applications: Across industries like healthcare, finance, and retail, LLMs optimize processes, improve decision-making through data insights, and enhance customer interactions. They are integral to automating routine tasks, ensuring regulatory compliance, and delivering personalized services.
- API Integration: Many LLM capabilities are accessible through APIs, enabling businesses to integrate advanced language processing functionalities into their existing systems and applications seamlessly.
LLMs are poised to continue transforming industries by driving efficiency gains, improving customer experiences, and enabling innovative applications across diverse sectors. Their adaptability and scalability make them a cornerstone of modern AI-driven solutions.
LLMs and Governance
The deployment and use of LLMs come with significant ethical and governance challenges. It is crucial to ensure that these models are used responsibly, mitigating risks such as bias, misinformation, and privacy concerns.
Key Governance Principles:
- Transparency: Clear documentation of how the model was trained, including the data sources and preprocessing steps.
- Fairness: Ensuring the model does not perpetuate or exacerbate biases present in the training data.
- Accountability: Establishing mechanisms for monitoring and addressing the impacts of LLM deployments.
- Privacy: Implementing safeguards to protect sensitive information used in training and operation.
Products Utilizing LLMs
LLMs are integral to many commercial products and services. Examples include:
- OpenAI’s GPT series: Used in various applications, from chatbots to content generation tools.
- Google’s BERT: Enhances search engine capabilities by understanding the context of search queries.
- Microsoft’s Azure Cognitive Services: Offers NLP tools powered by LLMs for sentiment analysis, entity recognition, and more.
Process to Build a Large Language Model
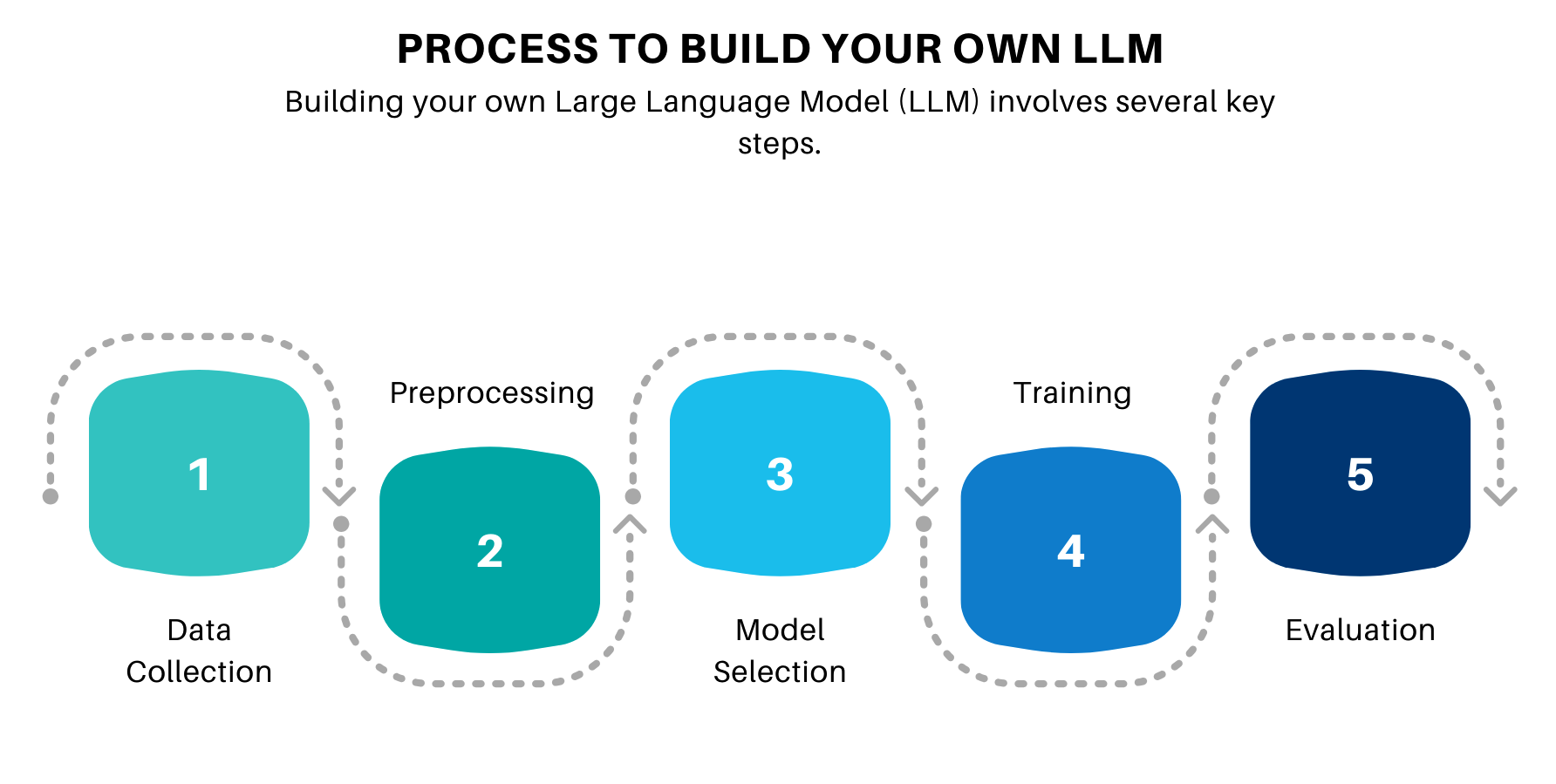
Building an LLM involves several critical steps, from data collection to deployment. Here’s a comprehensive guide to get you started:
Data Collection
The foundation of any LLM is the data it is trained on. Collecting a large and diverse dataset is crucial. You can use publicly available datasets or scrape data from various sources like books, articles, and websites.
Data Preprocessing
Once you have your data, the next step is to preprocess it. This involves cleaning and normalizing the text to ensure it is suitable for training. Common preprocessing steps include:
- Tokenization: Splitting text into words or subwords.
- Removing Stop Words: Filtering out common but unimportant words such as “and,” “the,” etc.
- Lowercasing: Converting all text to lowercase to maintain consistency.
- Lemmatization/Stemming: Reducing words to their base or root forms.
Model Selection
Choosing the right model architecture is crucial for building an effective LLM. Popular architectures include:
- Transformer: The backbone of most state-of-the-art LLMs, known for handling long-range dependencies in text.
- GPT (Generative Pre-trained Transformer): Developed by OpenAI, GPT models are among the most well-known LLMs.
- BERT (Bidirectional Encoder Representations from Transformers): Another popular model designed for understanding the context of words in a sentence.
Training
Training an LLM requires substantial computational resources. Here are the key steps:
- Set Up Environment: Use cloud platforms like AWS, Google Cloud, or local high-performance GPUs.
- Configure Hyperparameters: Set parameters such as learning rate, batch size, and the number of epochs.
- Training Process: Use frameworks like TensorFlow or PyTorch to train your model on the preprocessed data.
Here’s How to Train LLMs from Scratch
- Initialize the Model: Define the architecture and initialize the weights.
- Feed Data in Batches: Use mini-batch gradient descent to efficiently train on large datasets.
- Optimize: Apply optimization algorithms like Adam to adjust the weights based on the loss function.
- Regularize: Implement techniques like dropout to prevent overfitting.
- Validate: Periodically validate the model on a separate dataset to monitor performance.
How Do You Evaluate Large Learning Models?
Evaluating the performance of LLMs involves several metrics and techniques:
- Perplexity: Measures how well the model predicts a sample.
- Accuracy: The proportion of correct predictions.
- BLEU (Bilingual Evaluation Understudy): Used for evaluating the quality of machine-generated text.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation): Commonly used for summarization tasks.
- Human Evaluation: Involves human judges assessing the quality of the model’s outputs.
Deploying the LLM
Once your model is trained and evaluated, you can deploy it. Deployment options include:
- Cloud Services: Platforms like AWS SageMaker or Google AI Platform.
- On-Premises: Deploying on local servers or edge devices.
- APIs: Creating APIs to integrate your model with applications.
Conclusion
Large Language Models are powerful tools that have transformed how machines interact with human language. By understanding the fundamentals and following the steps outlined above, you can build your own LLM and leverage its capabilities for various applications. Whether you’re developing a chatbot, a content generator, or a translation service, the potential of LLMs is vast and exciting.