
Knowledge graphs are powerful tools for representing relationships between entities in a structured format. They are widely used in various industries like healthcare, finance, e-commerce, and more to organize vast amounts of data, enable advanced search functionalities, and provide better decision-making capabilities. However, building knowledge graphs requires extracting relevant entities and their relationships from raw text, which is where Named Entity Recognition (NER) comes into play.
Traditionally, NER has been the go-to method for entity extraction in knowledge graph construction. However, the emergence of Large Language Models (LLMs) has introduced new possibilities, making it necessary to compare the two approaches and evaluate which is more effective for building knowledge graphs. In this blog, we’ll dive into the details of how traditional NER and LLMs differ in building knowledge graphs and how each approach impacts the process.
What are Knowledge Graphs?
A knowledge graph is a network of interconnected entities and their relationships. It organizes information into a structured form that machines can interpret. The graph consists of:
- Nodes (Entities): Represent people, places, organizations, concepts, etc.
- Edges (Relationships): Define the connections between entities (e.g., ‘works at’, ‘is located in’).
Knowledge graphs are particularly useful in fields such as AI, data integration, and natural language processing (NLP), where the goal is to extract meaningful information from unstructured data.
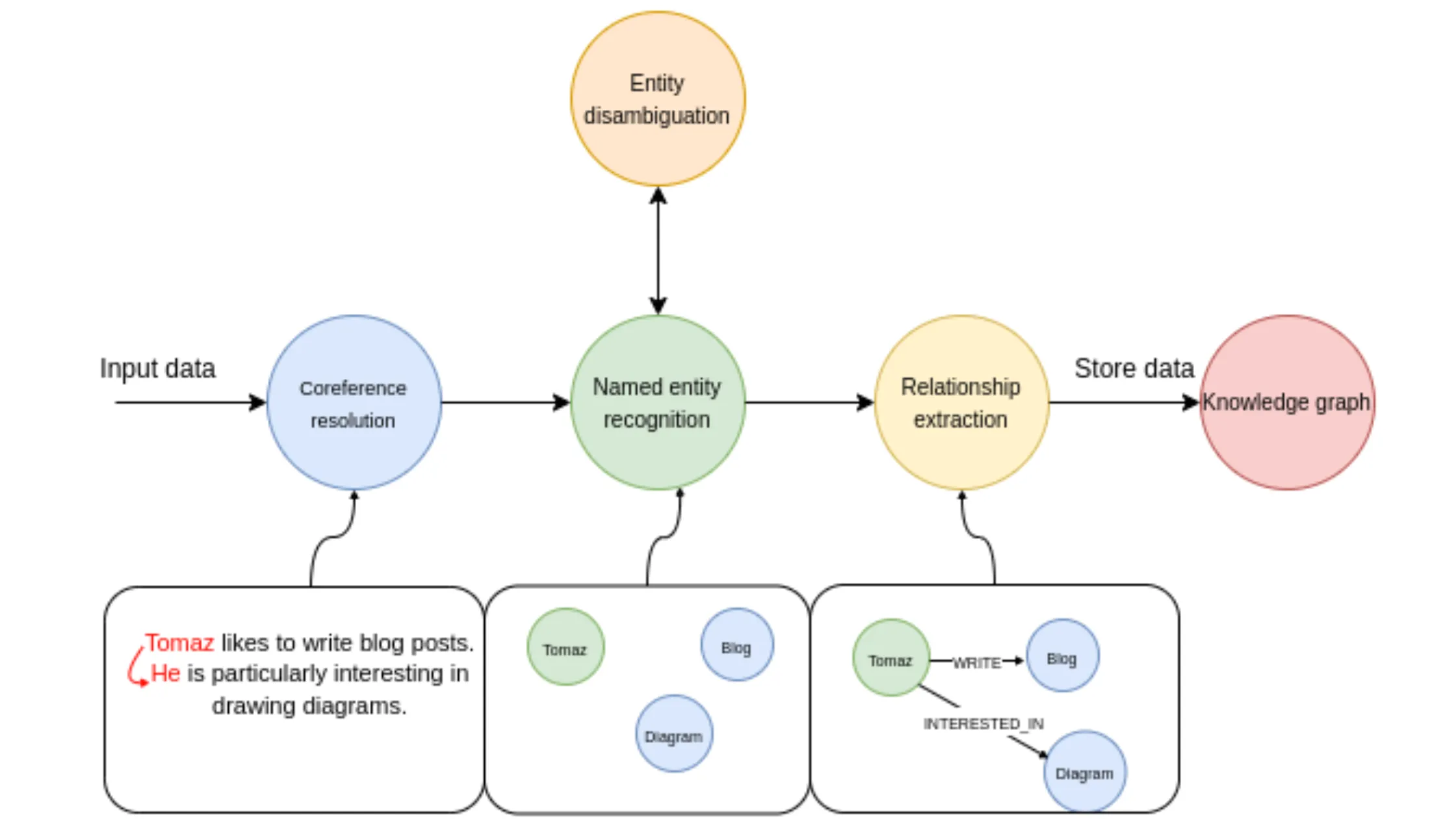
Traditional Named Entity Recognition (NER)
Named Entity Recognition (NER) is a subtask of information extraction that seeks to identify and classify named entities (such as people, organizations, locations, etc.) within a text. It is one of the earliest techniques used to extract information for building knowledge graphs.
How Traditional NER Works:
- Traditional NER models: Rely on predefined dictionaries and rule-based systems or machine learning algorithms that are trained on labeled datasets to detect entities.
- Rule-Based NER: Uses a set of rules or regular expressions to identify entities. For example, all capitalized words might be considered as proper nouns and therefore entities. This is fast but limited in flexibility.
- Machine Learning NER: Machine learning-based NER models are trained on annotated datasets. These models employ techniques like decision trees, conditional random fields (CRFs), or support vector machines (SVMs) to learn from text data.
- Deep Learning NER: Modern NER systems use deep learning models like recurrent neural networks (RNNs), long short-term memory (LSTM) networks, or transformers. These models can capture the context of words and perform better on unseen data.
Steps for Building Knowledge Graphs Using Traditional NER:
- Data Preprocessing: Clean and normalize the input text (remove special characters, lowercase, etc.).
- Entity Extraction: Use a trained NER model to extract entities from the text.
- Relationship Extraction: Identify relationships between entities using techniques like dependency parsing or co-occurrence analysis.
- Graph Construction: Represent the extracted entities as nodes and relationships as edges in a graph database (e.g., Neo4j).
- Graph Enrichment: Add additional entities and relationships by integrating data from multiple sources.
- Query the Graph: Use graph query languages like Cypher to search or traverse the knowledge graph.
One such approach is using neural models like GLiNER, which simplifies NER by leveraging deep learning techniques.
GLiNER Model for Named Entity Recognition:
The GLiNER model is pre-trained for Named Entity Recognition (NER) and is initialized here with domain-specific entity labels. The model then predicts entities based on the context in the text.
- Model Initialization: GLiNER is loaded using
GLiNER.from_pretrained(). A list of labels (e.g., “people”, “organizations”, etc.) is defined to guide the model in recognizing specific entity types. - Entity Extraction: The model scans the text for entities that match the provided labels. This is where GLiNER shines, as it can detect entities without needing predefined dictionaries or rigid rules.
from gliner import GLiNER
# Model Initialization
model = GLiNER.from_pretrained("numind/NuNerZero")
# Merging and Displaying Entities
# NuZero requires labels to be lower-cased!
labels = [
"people",
"organizations",
"concepts/terms",
"principles",
"documents",
"dates"
]
labels = [l.lower() for l in labels]
text = content_process
entities = model.predict_entities(text, labels)
entities = merge_entities(entities)
for entity in entities:
print(entity["text"], "=>", entity["label"])
Output

Challenges of Traditional NER
- Limited Scope: Traditional NER models are typically limited to predefined entity types like person, location, or organization. Custom entities (e.g., “brand names” or “chemical compounds”) require domain-specific training data.
- Manual Feature Engineering: NER models often rely on manual feature engineering, such as part-of-speech tagging or tokenization, which can be time-consuming and error-prone.
- Lack of Context Understanding: NER systems may struggle to understand the context in complex or ambiguous sentences. For example, the word “Apple” could refer to a fruit or a company, depending on the context.
Large Language Models (LLMs)
Large Language Models (LLMs), such as GPT-4, LLaMA, and OpenAI models, have transformed NLP by utilizing massive amounts of data and advanced deep learning techniques to understand language in a more nuanced and contextual way. Unlike traditional NER, LLMs can capture a broader understanding of language and relationships.
How LLMs Work in Knowledge Graph Construction:
- Contextual Entity Recognition: LLMs recognize entities based on context rather than fixed rules, making them more robust for varied and unseen data.
- Relationship Inference: LLMs can infer implicit relationships between entities by understanding natural language context and semantics.
- Dynamic Knowledge Updates: LLMs can process new, unseen data dynamically, making it easier to update knowledge graphs as new information becomes available.
Steps for Building Knowledge Graphs Using LLMs:
- Text Collection: Gather a large corpus of unstructured text from which to extract entities and relationships.
- Entity and Relationship Extraction with LLMs: Use an LLM to extract both entities and relationships from text. Prompt the model with specific queries like “Extract entities and their relationships from the following text.”
- Fine-Tuning for Domain-Specific Entities (Optional): Fine-tune the LLM on a domain-specific dataset to improve accuracy for specialized entities.
- Graph Construction: Structure the entities and relationships into a knowledge graph using a graph database like Neo4j or a custom-built solution.
- Graph Querying and Analysis: Use graph traversal algorithms to query relationships or discover new insights from the knowledge graph.
Large Language Models (LLMs) like GPT offer a flexible approach for extracting entities and relationships. With minimal setup, the model is prompted to identify entities (e.g., people, organizations) and infer relationships (e.g., works for, located in) directly from text. Unlike traditional models, LLMs understand context and return structured JSON data, making them ideal for dynamic, real-time knowledge graph construction.
import openai
import json
# Function to generate entities and relationships from the given text using OpenAI's API
def generate_entities_and_relationships(text, api_key):
# Set the OpenAI API key
openai.api_key = api_key
# Create the prompt that will be sent to the OpenAI API.
# The prompt asks the model to identify entities and relationships
within the provided text
# and format the response in JSON format.
prompt = f'''
Given the following text, identify the main entities and their relationships:
Text: {text}
Please provide the output in the following JSON format:
{{
"entities": [
{{"name": "Entity1", "type": "PersonType"}},
{{"name": "Entity2", "type": "OrganizationType"}},
...],
"relationships": [
{{"subject": "Entity1", "predicate": "works_for", "object": "Entity2"}},
{{"subject": "Entity2", "predicate": "located_in", "object": "Entity3"}},
...]}}
'''
# Send the request to the OpenAI API using the 'gpt-3.5-turbo' model.
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": "You are a helpful assistant that identifies
entities and relationships in text."
},
{"role": "user", "content": prompt}
]
)
# Extract and clean up the response by removing extra characters or
code format markers
result = response.choices[0].message["content"].strip().strip('```json').strip().strip('```')
return json.loads(result)
Output


Collab Link
How to extract entities using Traditional method and LLM
Comparison Between Traditional NER and LLM Approaches
| Comparative Factor | Traditional NER | LLMs |
|---|---|---|
| How do they identify entities? | Uses predefined rules or dictionaries and models trained on labelled datasets | Extracts entities contextually without predefined rules, based on massive pre-trained data. |
| How do they handle entity ambiguity? | Struggles with context; requires external disambiguation techniques | Resolves ambiguity by understanding the context (e.g., “Apple” as a company or fruit). |
| What about relationship extraction? | Requires separate relationship extraction techniques (e.g., dependency parsing). | Extracts implicit relationships directly from text, based on semantic understanding. |
| How adaptable are they to new domains? | Needs re-training with domain-specific data for each new task or entity type. | Adapts quickly with minimal additional training; can handle unseen domains using few-shot learning. |
| How do they understand context? | Limited to the immediate vicinity of the entity in a sentence; struggles with long-range dependencies. | Excellent at understanding long-range dependencies and multi-sentence contexts |
| What training is required? | Requires extensive labelled datasets and feature engineering for each new domain. | Pre-trained on large data, may require fine-tuning, but minimal data is needed. |
| How accurate are they across different domains? | High precision for predefined entities but struggles with unseen data and domain shifts. | More generalizable and flexible, performing well across varied domains even without fine-tuning. |
| Can they handle custom entities easily? | Requires substantial effort and data to train for custom or niche entities. | Easily customizable; few-shot learning allows quick adaptation to custom entities. |
| How scalable are they? | Hard to scale; adding new domains or languages requires extensive work. | Highly scalable across domains, tasks, and languages without major retraining. |
| Do they support multiple languages? | Typically limited to a few languages unless re-trained on specific multilingual datasets. | Supports multiple languages out of the box, as LLMs are trained on diverse multilingual corpora. |
| What about performance speed and deployment? | Lightweight and faster, suitable for low-resource environments. | Computationally intensive; may require optimization for real-time performance, such as model distillation. |
| How are knowledge graphs enriched with them? | Requires manual intervention to add new relationships or entities. | Can dynamically update and enrich knowledge graphs by reprocessing new data automatically. |
| How flexible are they with complex relationships? | Limited flexibility often only works well with simple, direct relationships. | Flexible, capable of extracting complex or implicit relationships based on context. |
| How much maintenance do they require? | Requires frequent retraining and updating of rules or models. | Requires occasional fine-tuning but minimal ongoing maintenance. |
Best Practices for Building Knowledge Graphs with LLMs
- Leverage Pre-trained Models: Use pre-trained LLMs to extract entities and relationships without needing extensive labelled datasets.
- Customize for Domain-Specific Needs: Fine-tune LLMs on specific industries (e.g., healthcare, finance) to enhance performance on niche tasks.
- Utilize Knowledge Distillation: Apply knowledge distillation techniques to convert complex LLM outputs into structured knowledge graph data.
- Evaluate for Accuracy: Continuously evaluate the accuracy of extracted entities and relationships using human-in-the-loop or automated evaluation techniques.
- Optimize for Performance: Since LLMs can be computationally expensive, optimize the model for performance by deploying lighter versions for real-time applications.
Also Read:
From RAG to GraphRAG: Transforming Information Retrieval with Knowledge Graphs
Conclusion
Both Traditional NER and LLM-based approaches have their place in building knowledge graphs. Traditional NER is reliable for structured, predefined entity types and works well in domains with established taxonomies. However, LLMs provide a more flexible, context-aware, and scalable solution for extracting entities and relationships from vast, unstructured data sources.
For projects where context, nuance, and scalability are essential, LLMs are the superior choice. By leveraging their understanding of natural language, LLMs make it easier to build dynamic and highly contextual knowledge graphs that evolve as new information becomes available.
The future of knowledge graphs lies in the hybridization of both approaches, combining the precision of traditional NER models with the adaptability and power of LLMs to create robust systems capable of handling increasingly complex data landscapes.