
Cache-Augmented Generation (CAG) has emerged as an innovative approach for enhancing language model performance by leveraging preloaded knowledge. It provides a streamlined, efficient alternative to Retrieval-Augmented Generation (RAG), particularly for tasks where knowledge is stable and predictable. In this blog, we will dive into the technical aspects of CAG, compare it with RAG, and explore its applications and limitations.
Introduction to Cache-Augmented Generation (CAG)
Cache-Augmented Generation is a method where relevant knowledge is preloaded into the context or memory of a language model. During inference, the model uses this preloaded information to generate responses, bypassing the need for real-time retrieval from external sources. This preloading is achieved through the model’s key-value (KV) cache, which encapsulates the model’s inference state.
Key Characteristics of CAG
- Preloaded Knowledge All necessary documents or facts are loaded into the model’s context before inference.
- Reduced Latency Eliminates real-time retrieval, resulting in faster responses.
- Simplified Architecture No integration of retrieval components, reducing system complexity.
How Does CAG Work?
The CAG framework operates in three main phases:
1. External Knowledge Preloading
A curated collection of documents, D={d1,d2,…,dn}, relevant to the target application, is preprocessed and encoded into a precomputed key-value (KV) cache:
Ckv = KV-Encode(𝒟)
This preloading phase incurs a one-time computational cost, making the framework highly efficient for subsequent queries. The precomputed KV cache is stored either in memory or on disk for quick access during inference.
2. Inference
During the inference phase, the precomputed KV cache Ckv is loaded alongside the user’s query (Q):
R = M(Q|CKV)
The model leverages the cached context to generate responses, thereby eliminating the latency and risks associated with dynamic retrieval processes. By concatenating the preloaded knowledge and the user query:
P=Concat(𝒟,Q)
the model achieves a cohesive understanding of the information.
3. Cache Reset
To sustain system performance, the KV cache can be reset efficiently by truncating newly appended tokens(t1,t2,…,tk):
CKVreset = Truncate(CKV,t1,t2,…,tk)
This allows for rapid reinitialization without the need for a complete reload, ensuring the framework maintains high responsiveness.
Visual Comparison
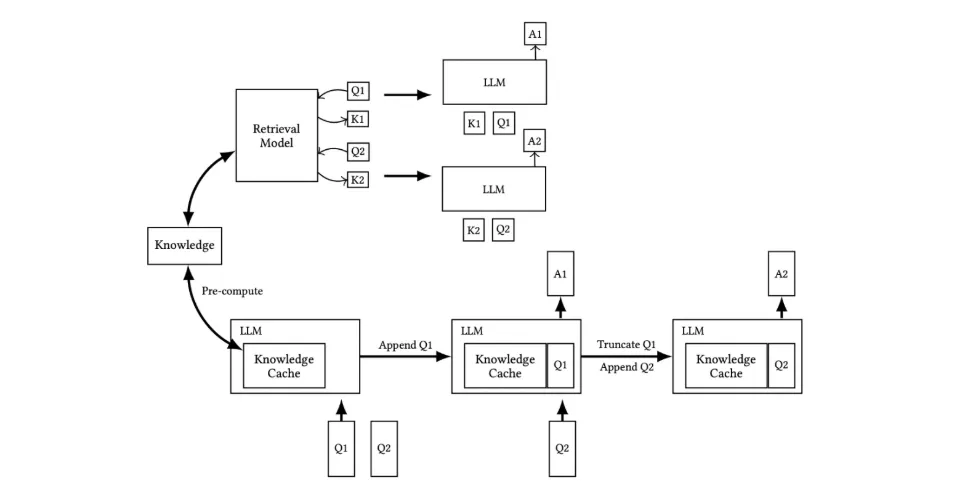
Comparison of Traditional RAG and our CAG Workflows
The upper section illustrates the RAG pipeline, including real-time retrieval and reference text input during inference, while the lower section depicts our CAG approach, which preloads the KV-cache, eliminating the retrieval step and reference text input at inference.
Comparison: CAG vs. RAG
Retrieval-Augmented Generation (RAG) is another approach where external knowledge is retrieved in real-time to assist response generation. Let’s compare these two methods:
Feature Comparison
| Feature | Retrieval-Augmented Generation (RAG) | Cache-Augmented Generation (CAG) |
|---|---|---|
| Knowledge Source | External database or search engine | Preloaded into model context |
| Response Time | Slower due to retrieval latency | Faster due to preloaded knowledge |
| Complexity | Requires retrieval and integration | Simpler, no retrieval needed |
| Scope of Knowledge | Dynamic and large-scale | Static and limited to preloaded data |
Experimental Results and Comparison of Generation Time
To further assess the performance of Cache-Augmented Generation (CAG) compared to Retrieval-Augmented Generation (RAG), experiments using datasets such as SQuAD and HotPotQA were conducted. These experiments evaluate the generation time, latency, and overall system performance under different configurations of reference text lengths and document counts. (Below experiments reported in the research paper)
Overview of the SQuAD and HotPotQA Test Sets
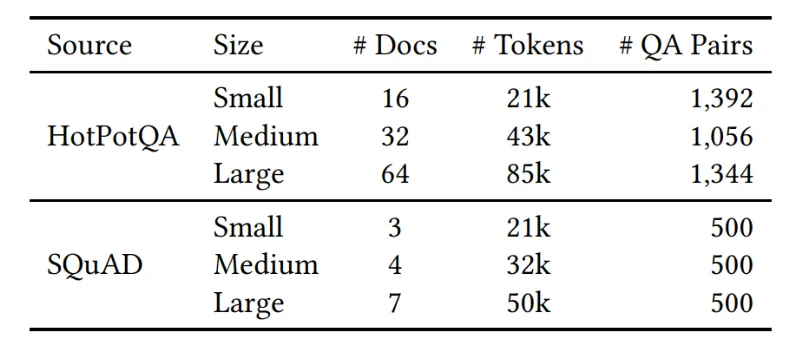
An overview of the SQuAD and HotPotQA test sets, categorized by varying reference text lengths, detailing the number of documents, questions, and corresponding answers for each configuration.
Experimental Results
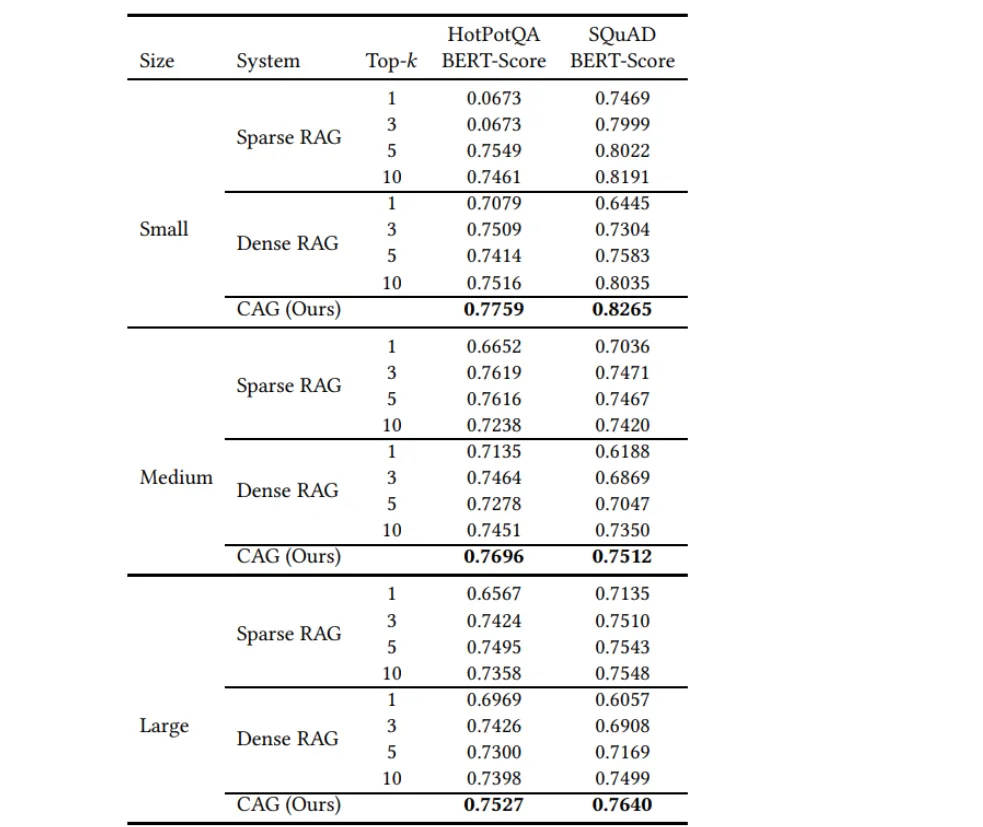
- Superior Performance The proposed Cache-Augmented Generation (CAG) method consistently achieves the highest BERTScore, outperforming both dense (e.g., OpenAI Indexes) and sparse (e.g., BM25) RAG systems.
- Elimination of Retrieval Errors Preloading the entire test set context ensures comprehensive reasoning over relevant information, bypassing issues of incomplete or irrelevant retrievals in RAG systems.
- Robustness for Complex Tasks CAG excels in tasks requiring holistic understanding of source material, offering a distinct advantage over retrieval-dependent methods.
Comparison of Generation Time
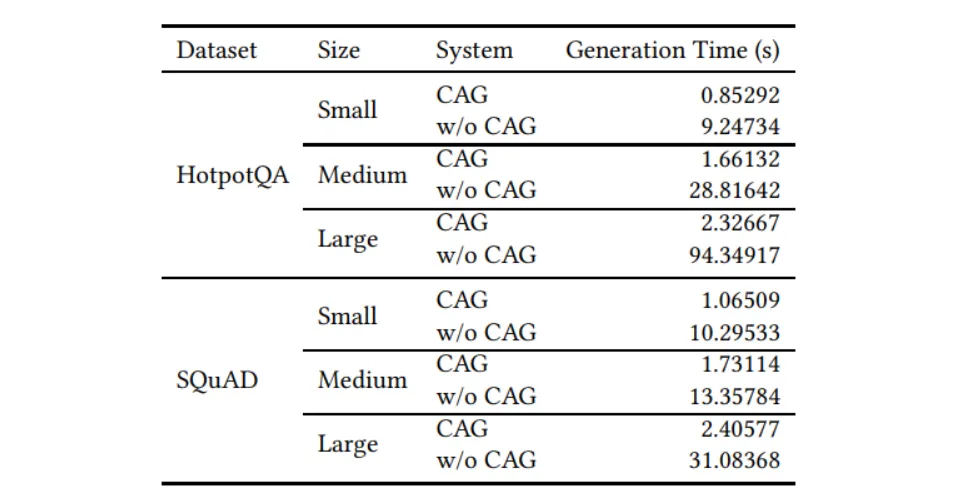
- Efficiency Advantage CAG significantly reduces generation time compared to standard in-context learning, especially with longer reference texts.
- Preloaded KV-Cache By preloading the KV-cache, CAG avoids the overhead of real-time computation during inference.
- Scalability The approach ensures consistent efficiency gains as the length of the reference text grows, highlighting its scalability for tasks requiring extensive contextual information.
Example: How RAG and CAG Work in a Business Context
Scenario: Customer Support for a SaaS Product
A user asks, What are the benefits of upgrading to the premium plan?
Using RAG (Retrieval-Augmented Generation):
Query Submission:
The user submits the query, What are the benefits of upgrading to the premium plan?
Real-Time Retrieval:
The system searches a database or knowledge base for relevant documents.
It retrieves content such as:
- The premium plan offers advanced analytics and unlimited integrations.
- Customers with the premium plan get priority support and additional storage.
Response Generation:
The system combines the retrieved data to generate a response:
The premium plan provides advanced analytics, unlimited integrations, priority support, and additional storage.
Using CAG (Cache-Augmented Generation):
Preloaded Knowledge Cache:
Beforehand, the system has preloaded key information about the premium plan, such as:
- The premium plan includes advanced analytics, unlimited integrations, priority customer support, additional storage, and customizable dashboards.
Query Submission:
The user submits the same query, What are the benefits of upgrading to the premium plan?
Response Generation:
The system instantly generates a response using the preloaded cache:
The premium plan offers advanced analytics, unlimited integrations, priority support, additional storage, and customizable dashboards.
Code Implementation:
To understand how Cache-Augmented Generation (CAG) can be applied in a business context, such as SaaS customer support, the above link provides a complete Python implementation (POC) for just an example of how the cache part works. This implementation leverages a preloaded knowledge cache to instantly generate responses to user queries using OpenAI’s GPT-4 model.
Key Features of the Implementation:
- Preloaded Knowledge Cache The code initializes a static dataset containing details about the SaaS product (e.g., premium plan features). This cache allows the system to respond quickly and accurately to queries.
- Dynamic Query Handling The
query_with_cagfunction combines the user’s query with the preloaded knowledge to generate a context-aware response. - LLM Integration The implementation uses OpenAI’s GPT-4 model via the OpenAI Python library to generate responses.
from openai import OpenAI
client = OpenAI(api_key="KEY")
# Preloaded Knowledge Cache
knowledge_cache = """
The premium plan includes:
- Advanced analytics
- Unlimited integrations
- Priority customer support
- Additional storage
- Customizable dashboards
"""
# Define Support Query Function
def query_with_cag(context: str, query: str) -> str:
"""
Query the LLM with preloaded context using Cache-Augmented Generation for SaaS customer support.
""" # Construct the prompt
prompt = f"""
Context:
{context.strip()}
Query:
{query.strip()}
Answer:"""
try:
# Call the OpenAI API
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "You are a helpful assistant for SaaS customer support."},
{"role": "user", "content": prompt}
],
max_tokens=150,
temperature=0.5
)
# Extract and return the response
return response.choices[0].message.content.strip()
except Exception as e:
# Handle API errors gracefully
return f"Error querying the LLM: {e}"
# Example Query
if __name__ == "__main__":
# Customer's query
query = "What are the benefits of upgrading to the premium plan?"
# Generate response using the preloaded cache
response = query_with_cag(knowledge_cache, query)
print("Answer:", response)
Output

Advantages of CAG
- Reduced Latency By eliminating real-time retrieval, CAG ensures near-instantaneous response times, making it ideal for latency-sensitive applications.
- Simplified Architecture CAG removes the need for complex retrieval pipelines, simplifying implementation and maintenance.
- Error Minimization Preloading ensures that only the most relevant information is used, reducing the risk of errors associated with irrelevant document retrieval.
Limitations of CAG
- Limited Knowledge Scope CAG can only use preloaded information. If a query falls outside the cached scope, the model may fail to provide accurate responses.
- Static Knowledge Updating the cache requires reloading the model’s context. This makes it less suitable for tasks requiring dynamic or frequently updated data.
- Memory Constraints The amount of knowledge that can be preloaded is limited by the model’s memory capacity, making it impractical for very large knowledge bases.
Use Cases of CAG
CAG excels in scenarios where the knowledge is stable and well-defined. Examples include:
- FAQs Preloading frequently asked questions and answers for customer support.
- Domain-Specific Chatbots Healthcare, legal, or technical support where the scope of information is predictable.
- Document Summarization Summarizing predefined sets of documents.
When to Choose CAG over RAG
- Choose CAG If:
- The knowledge base is stable and does not require frequent updates.
- Fast response times are critical.
- System simplicity is a priority.
- Choose RAG If:
- The knowledge base is large, dynamic, or frequently updated.
- Real-time access to new information is required.
- Flexibility in answering a wide range of queries is essential.
Conclusion
Cache-Augmented Generation (CAG) offers a compelling alternative to Retrieval-Augmented Generation (RAG) for specific use cases. By preloading knowledge, it achieves faster responses, reduces complexity, and minimizes retrieval-related errors. While it’s not suitable for every scenario, CAG shines in applications where knowledge is predictable and stable. By understanding its strengths and limitations, developers can make informed decisions about when to leverage this innovative approach.
References
Chan, B. J., Chen, C.-T., Cheng, J.-H., & Huang, H.-H. (2025). Don’t Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks. arXiv, 2024.